简介
Semgrep是一款轻量而强大的代码扫描工具,而代码扫描很难避免的一个问题就是误报量大。所以针对最近遇到的几种类型的误报简单展开下。
正题
规则类型
正题开始先了解几个常用的规则类型:
| 类型 | 含义 |
|---|---|
| patterns | 其中的子规则都是and关系 |
| pattern-either | 其中的子规则都是or关系 |
| pattern-not | 不匹配其中的规则 |
| pattern-not-inside | 匹配不在其表达式中的代码 |
清除误报
具名参数
Spring框架中的NamedParameterJdbcTemplate提供了具名参数的用法,通常预编译时是使用?作为参数占位符:
1 | String query = "SELECT * FROM user_data WHERE user_name = ? "; |
而具名参数是使用:参数名作为占位符,用法如下:
1 | String sql = "select first_detail,last_detail from users where user_name = :username and age <= :age "; |
具名参数以名称而不是位置进行参数绑定,更易维护。以上述这种用法为例,最终将生成一个预编译创造器,底层实现仍然是JdbcTemplate,使用提供的query方法进行查询,RowMapper用来将查询到的数据逐行映射到对象中。和使用PreparedStatement进行参数绑定一样,都可以实现预编译并避免SQL注入风险。
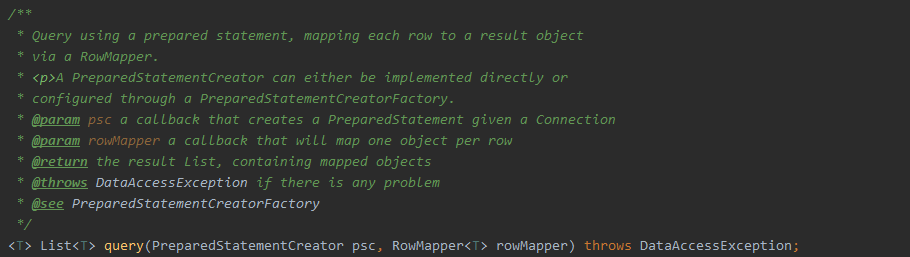
针对这种误报,规则中只需检查两点,也就是只要正确使用了NamedParameterJdbcTemplate模板进行数据库操作即可。为了保证这两点,一开始我使用了下面这个规则,$SQL、 $X 都代表变量,...在Semgrep中表示任意值,相当于正则表达式中的.*。校验使用了map对象(进行传参)和NamedParameterJdbcTemplate实例化后的对象,这个规则可以消除上述用法的误报。但是,具名参数不只是这一种用法,实例化后的对象名也不会是固定的。
1 | - pattern-not: | |
所以,我查看了下NamedParameterJdbcTemplate.java中所有的函数,发现都使用了预编译:D。于是规则改成了这样:
1 | - pattern-not: | |
由$NPJT匹配所有NamedParameterJdbcTemplate实例化后的对象名,调用了其中函数的都属于误报。这个规则表面上看起来运行的不错,运行之后也确实生效了。但是,semgrep的检测方法不同于cobra和fortify,它是依靠模式匹配的方式去检测的,可以看出是一种类似伪代码的表达方式。如果其中测试代码的顺序和规则不一致的话,是不会被命中的。也就是说,如果源代码改成这样:
1 | NamedParameterJdbcTemplate namedParameterJdbcTemplate = new NamedParameterJdbcTemplate(jdbcTemplate); |
只调换了下SQL行和实例化行的位置,上面那条误报清除规则就不起作用了….
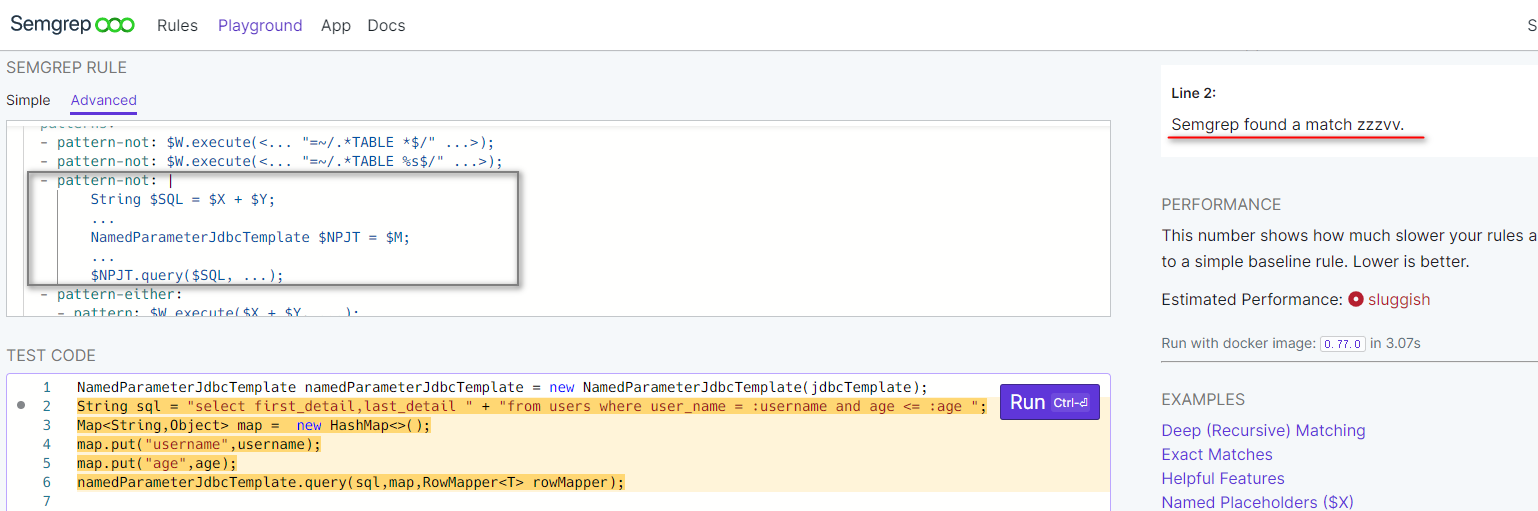
顺势把规则中的两行代码也调换下试试:
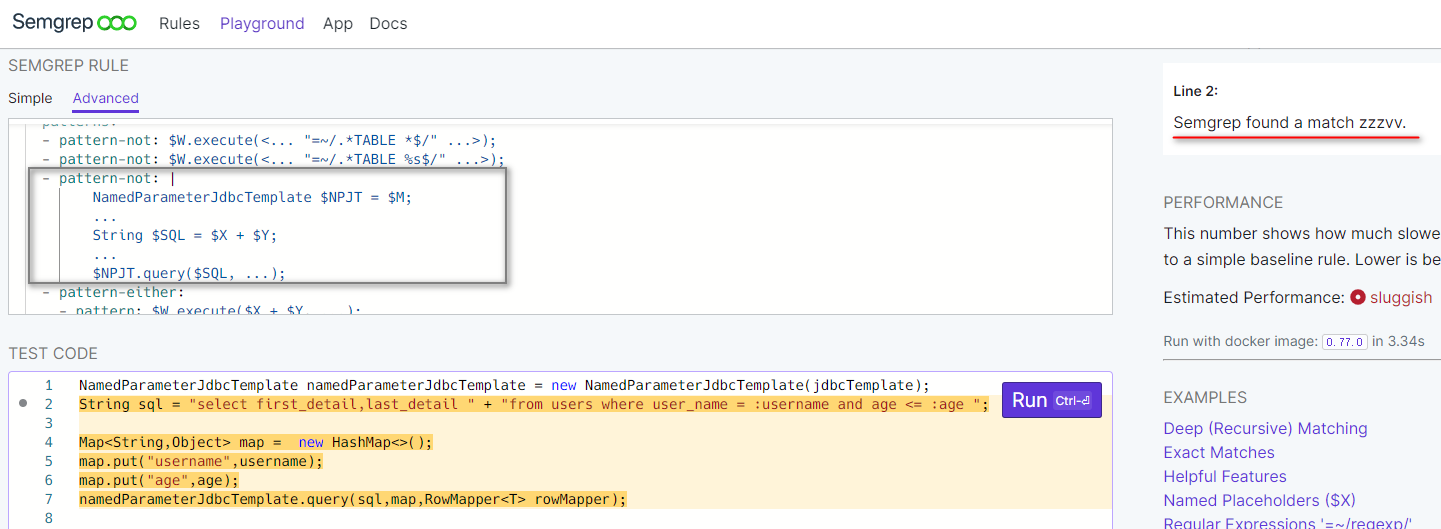
这次清除规则还是没有生效,很令人头大…. 换成pattern-not-inside试试:
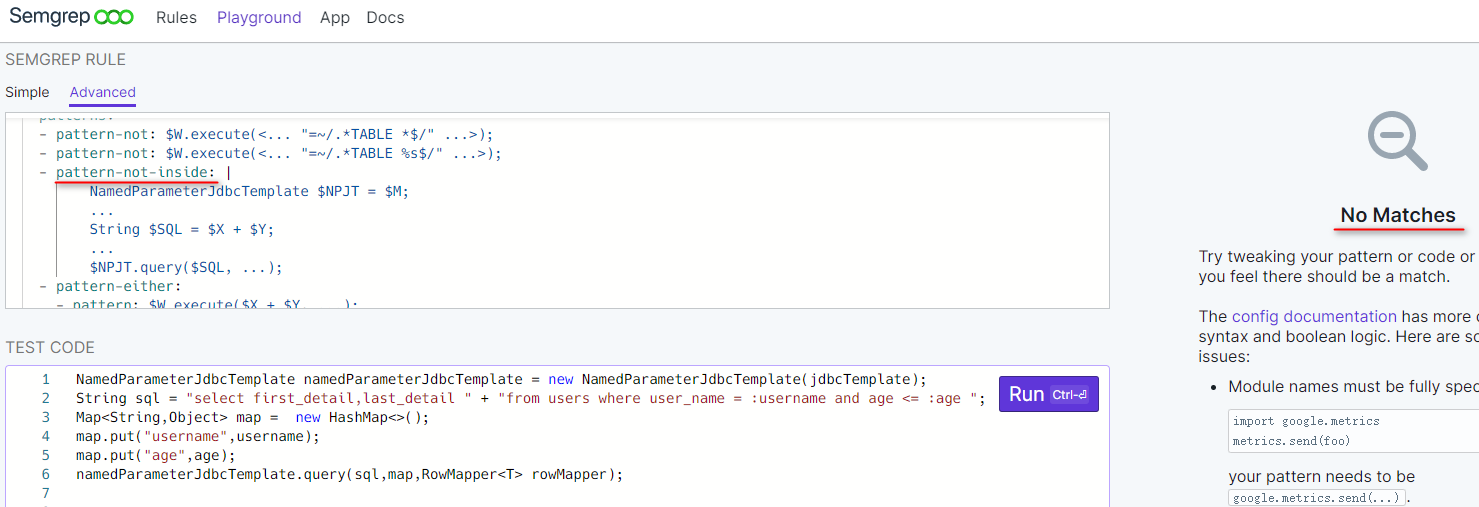
pattern-not-inside模式下这个误报被清除掉了。pattern-not和pattern-not-inside一般情况下的检出是一样的,只在一些特殊情况会有些细微差异。pattern-not-inside关注的是检出不在其规则表达式中的代码,以下是官方定义:
1 | The pattern-not operator is the opposite of the pattern operator. It finds code that does not match its expression. |
其实这两个模式的定义还是比较容易混淆的,我目前也领悟的不是很深刻,如果有独到理解的我们可以讨论一下:D。另外具名参数并不只提供了query()方法,还有execute()、update、queryForList()等等。
常量相加
这种类型的误报应该是最常见的,sql语句中没有变量,全部是常量。在Semgrep Playground中用工具自带的规则进行测试也可以看到确实被检出。
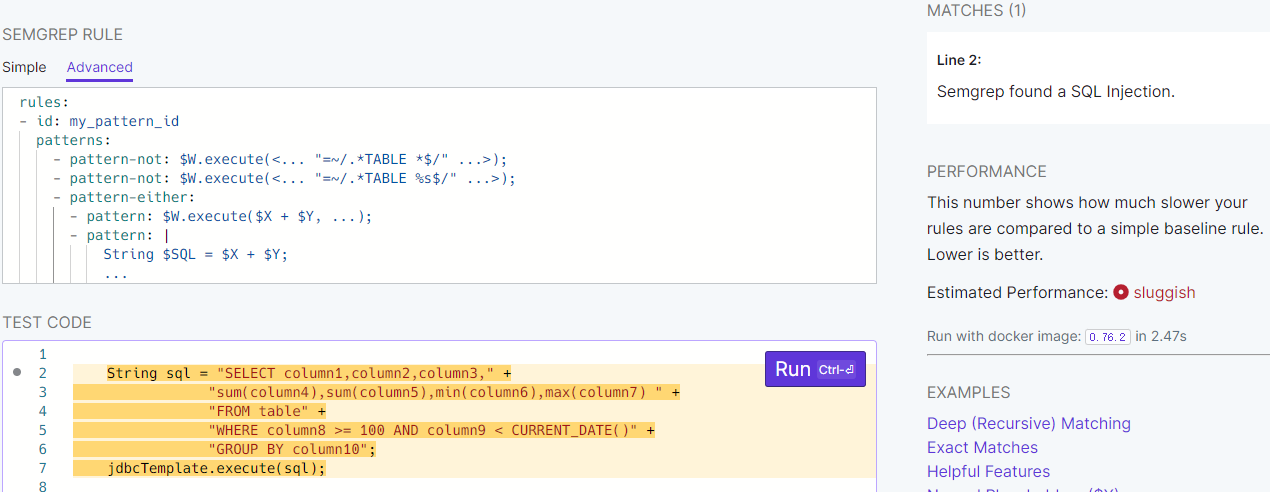
这种情况要清除误报可以用下图中的pattern:
1 | - pattern-not: | |
$SQL用来表示变量,"..."表示常量,$METHOD()表示任意方法,这个规则用起来很爽,可以清掉一大片误报,包括上一个具名参数的误报也可以用这个清除掉,但它有个致命的缺点,就是会带来漏报。当测试代码改成这样,先是常量相加,再拼接一个变量时,这个漏洞就不会被检出了:
1 | String sql = "SELECT column1,column2,column3," + |
所以针对常量相加的误报,还是要具体情况具体分析,一个比较简单的办法就是看下工具自带的规则,针对性的提炼规则:
1 | 工具自带: |
1 | 工具自带: |
总结
总的来说semgrep还是一款很轻量好用的白盒扫描工具,规则也易于理解,也许难点就在于不断调试、推翻、再调试的这个过程。今天介绍的两种类型也比较简单,有任何片面不足的地方也期待指正:D。